论文Learning to Extract Conditional Knowledge for Question Answering using Dialogue提出了 conditional knowledge base(CKB),存储的信息格式为 (subject, predicate, object|condition)。当用户问句缺少必要条件(condition)时,自动用 dialogue model 来向用户提问获取必要信息,再进行回答。
简化版过程,从训练数据的用户问句里抽取实体,频率最高的 50% 作为 subject,剩余的作为 candidate condition。对于每一个 subject,学习用户问句的 pattern 和 condition (类似于关系抽取),然后学习 pattern 和 condition 的 embedding,并对其进行聚类得到 pattern cluster 和 condition cluster,再从聚类信息和 QA 对中抽取信息组成 (subject, predicate, object|condition) 作为 CKB。
当用户提问并没有清楚的指定条件时,就可以用 dialogue model 向用户提问获取 condition,具体过程如下

用户界面演示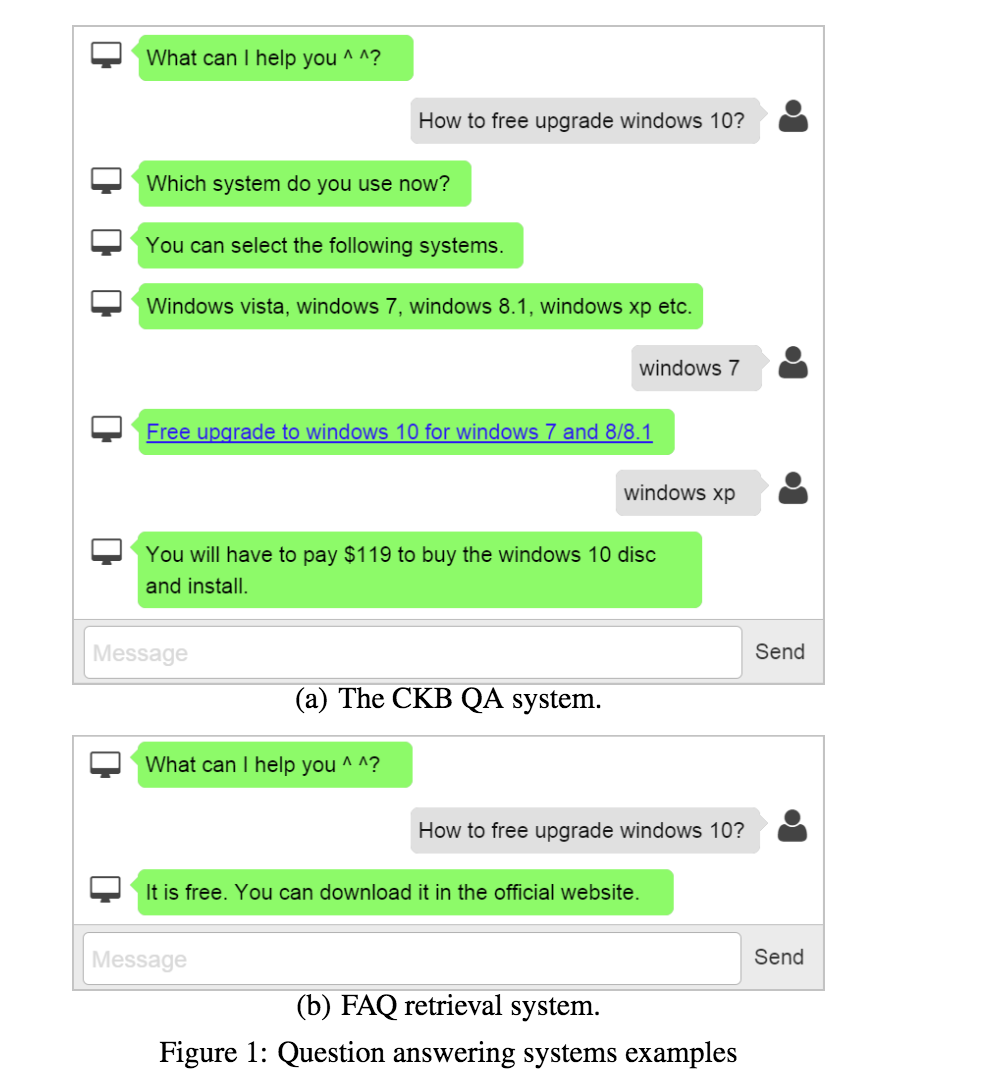
Pattern mining
这一步的目的是学习 pattern 和 condition,用 bootstrapping 方法。
input: all questions with the same subject
output: question patterns; conditions
|
|
输入有两个 entities, windows_xp 和 windows_10,windows_10 被选为 subject,那么 windows_xp 就是 candidate condition,然后我们产生了 pattern “SLOT0 free upgrade windows_10”,当遇到下面新的输入时,win7 就会被抽取作为 candidate condition,因为输入和 pattern 正好匹配
|
|
一个问题是怎么来产生初始的种子,方法是
- remove question words
- use special type of words for question chucking
special type of words: prepositions, copulas, interrogatives, conjunctions, modal verbs, personal pronouns, verbs, some stop words - add remaining parts into seed dictionary
Pattern Aggregation
这一步非常简单,就是做一个 groupby,把上一步产生的相同 pattern 不同 condition 的输出按 pattern 分组,见 Step2
Condition and Pattern Representation Learning
不同的 pattern 可能反应了相同的 user intent,这一步的目的就是对 pattern 进行聚类,目的是希望每一个类别代表一个 user intent。同时,对聚类后的每一个 pattern cluster 的 condition 进行聚类,聚类标准是在当前 condition 下的问题是否拥有相似的 answer。
首先学习 pattern 和 condition 的 embedding。对此论文提出了一种新的算法 patterns and conditions jointly embedding algorithm(PCJE),由 condition embedding model, pattern embedding model 和 alignment model 三个 model 组成,目标函数是三个 model 的目标函数之和。
Condition embedding model 主要看 $p(c_k, c_m)$,通过 Skip-gram 来学习 question, answer, condition pairs 的嵌入向量,要注意的是,这里 Skip-gram 的目标函数最大化 $J_c = J(\theta) + \beta E_c$,其中 $ J(\theta) $ 是 Skip-gram 原本的目标函数, $E_c$ 是正则化后的 condition pair($c_k,c_m$) 的联合概率,如下
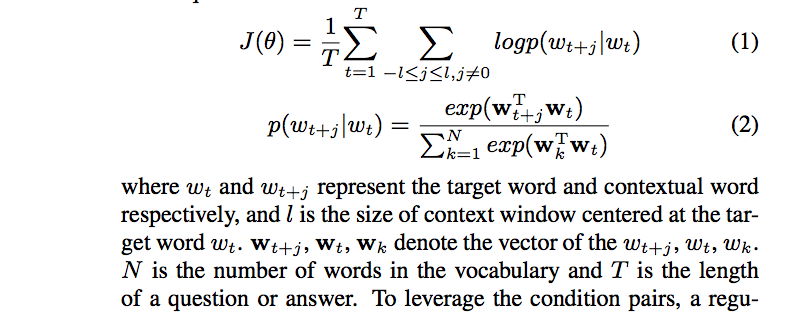
$$p(c_k,c_m) = {1 \over 1+exp(-c^T_kc_m)}$$
$$E_c=\sum_{(k,m) \in P_c} w^c_{km}logp(c_k,c_m)$$
Pattern embedding model 主要看 $p(v_k, v_m)$
Alignment model 主要看 $p(c_k, v_m)$,通过 pattern 和 condition 的共现关系来对齐两个向量空间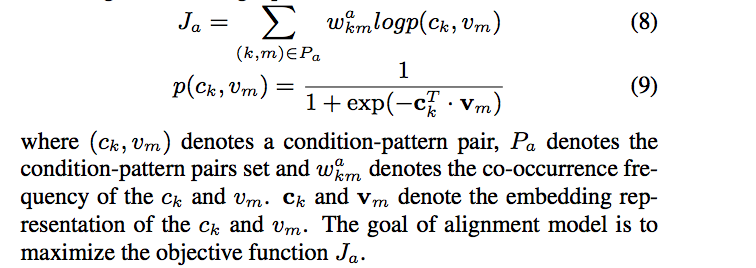
整体需要优化的目标函数
$$J=J_c+J_p+J_\alpha$$
Conditions and Patterns Clustering
input: patterns, conditions, embedding representations
output: pattern clusters, condition clusters
patterns in the same cluster will share the same intent, which is predicate in classical KB.
用了下面的层次聚类算法
Conditional Knowledge Base Construction
input: pattern clusters, condition clusters
output: (Subject, Predicate, Object | Condition) triples
要知道并不是所有的 condition 都是重要的,这一步骤会过滤一些不重要的 condition。这里提到了一个概念 missing percentage of slots,指的是能够匹配 pattern 然而却没有 slot 的情况,比如下面的例子,对输入而言,尽管匹配了 pattern,但 SLOT0 是缺失的。
对每个 slot 计算 missing percentage (of slots),然后把 slot 分为下面三种类型
- 只有一个 cluster 的 slots(没有询问的必要)
- 基本上不会被忽略的 slots
- 几乎没有用户会在意的 slots
第一种直接过滤,第二种也就是过滤 missing percentage 大于 0.7 的 slot,第三种也就是过滤 missing percentage 小于 0.3 的 slot,剩下的 slots 才是重要的,组成 (Subject, Predicate, Object | Condition) 格式存到 CKB 中。

Subject: 选定的 entity
Predicate: 同一 cluster 的若干 pattern,用频率最高的若干个单词/短语作为代表性的 predicate
Object: 根据 answer set 与 pattern cluster 的 average embedding 的 cosine similarity 来选择 top answer 作为 object
Condition: 同一 cluster 的若干 condition
Dialogue Model Construction
两个任务,看 input question 是否匹配 pattern,缺失的 condition 是否重要,如果重要,那么,提问并提供候选项来让用户选择,填充 slot,返回答案

